HDFS helps provide high performance access to data across the cluster. It helps to scale out the data storage by distributing the data on multiple data nodes.
Each node of the Hadoop cluster is a commodity hardware. Hadoop makes uses of the combined computational power of many machines to produce super-computing outcomes and thus works on Big-data effectively.
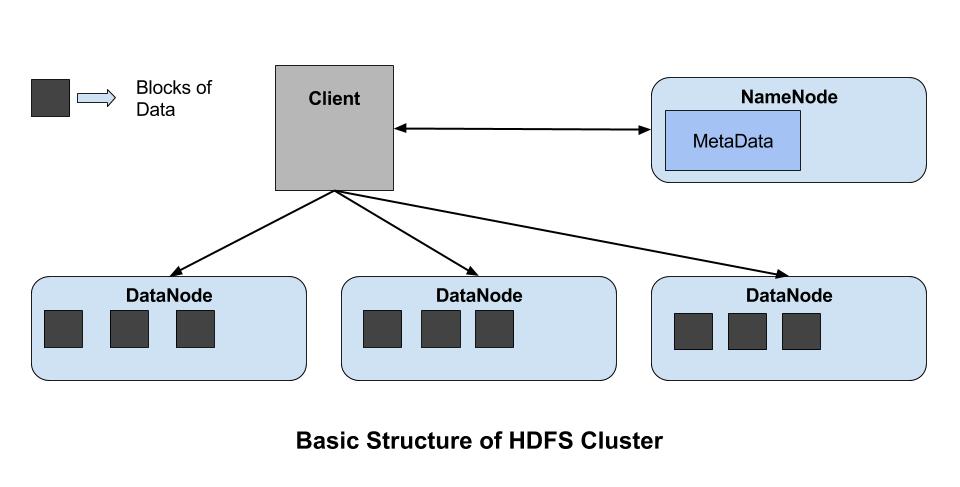
The cluster nodes are classified as Name-nodes and Data-nodes.
Data nodes have the primary function of storing files while name-nodes manage the location of the files in data-nodes.
Data at the data-nodes is stored in the form of blocks.
Each block is 64 Mb or 128 Mb in size (as setup in configuration), unlike the 4Kb block size of most conventional operating systems.
Block size affects the indexing and space wastage of the cluster and is dependent on the average size of files that are to be stored.
HDFS is designed to be fault-tolerant. Due to use of commodity hardware, it expects the nodes in its clusters to fail. Hence to maintain data availability, it makes use of replication.
Each block of data is replicated in three different nodes by default.
If a node with a copy of the block goes down, the other two copies are used to replicate the data onto a new node. Thus maintaining data availability with the help of replication.


Leave a comment