One way to effectively manage scaling data is Sharding.
What exactly happens in Sharding ?
Horizontal splitting of data across multiple tables is termed as Sharding.
In simple words, if you have a list if items and you tear it into two pieces then each of the piece (which has a certain number of items) can be termed as a Shard.
In Database Sharding, the schema of the original table is replicated into each of the shards.
Data is divided into the shards based on a shard key.
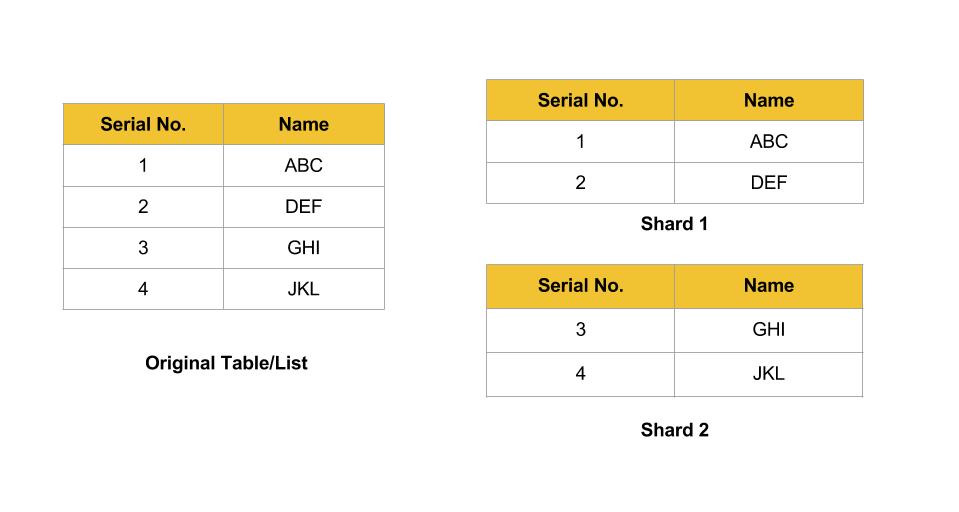 |
| Sharding of a table |
Sharding basically distributes the tables onto different servers such that the load is balanced equally.
The most performance effective sharding would take place when the table keys are sorted and hence handling of the shard keys would be easier.
An important point to be considered is that sharding is more effective when data is manipulated less often. More preferred tables would be those that are written once and read multiple times.
If data is added or deleted multiple times, it would lead to a difficulty in managing the shards.
Apache HBase makes use of Auto-Sharding to manage the data.
Advantages:
- Tables are distributed across multiple databases.
- Reduced load on a single database server.
- Helps achieve horizontal scalability, thus increasing the overall storage capacity.
Disadvantages:
- A dependency on the inter connectivity of the database servers is most important.
- When a posed query needs to make use of multiple shards, performance may be hampered.


Simplified
LikeLike
Nicely explained
LikeLike